Comp578 Susan Portugal Fall 2008
Assignment 4 September 25, 2008
4.8.2 Consider the training examples shown in Table 4.7 for a binary classification problem.
Table 4.7 Data Set
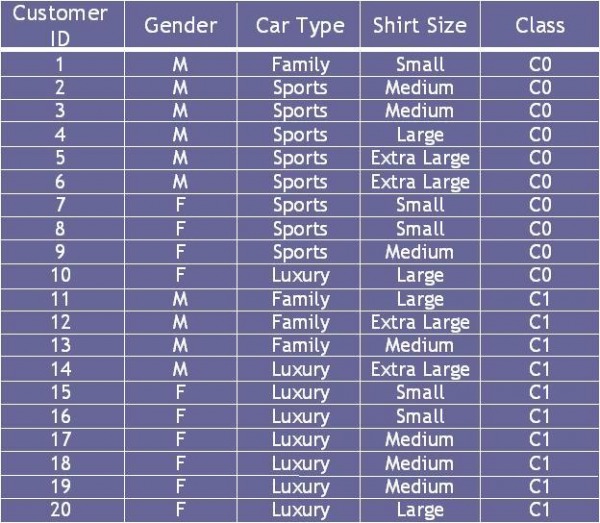
(a) Compute the Gini index for the overall collection of training examples.

(b) Compute the Gini index for the Customer ID attribute.
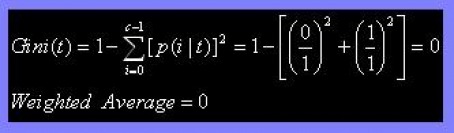
(c) Compute the Gini index for the Gender attribute.

(d) Compute the Gini index for the Car Type attribute using multiway split.

(e) Compute the Gini index for the Shirt Size attribute using multiway split.

(f) Which attribute is better, Gender, Car Type, or Shirt Size?
When comparing Gender, Car Type, and Shirt Size using the Gini Index, Car Type would be the better attribute. The Gini Index takes into consideration the distribution of the sample with zero reflecting the most distributed sample set. Out of the three listed attributes, Car Type has the lowest Gini Index.
(g) Explain why Customer ID should not be used as the attribute test condition even though it has the lowest Gini.
Customer ID should not be used as the attribute test condition because each attribute is unique.
2.8.3 Consider the training examples shown in Table 4.8 for a binary classification problem.
Table 4.8 Data Set
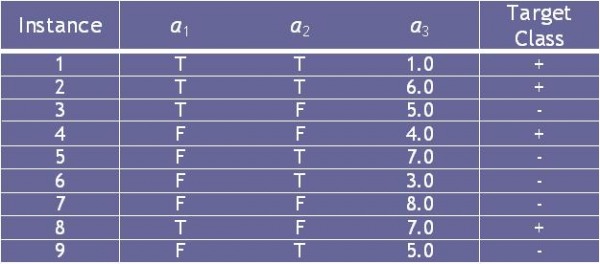
(a) What is the entropy of this collection of training examples with respect to the positive class?

(b) What are the information gains of a1 and a2 relative to these training examples?

(c) For a3, which is a continuous attribute, compute the information gain for every possible split.
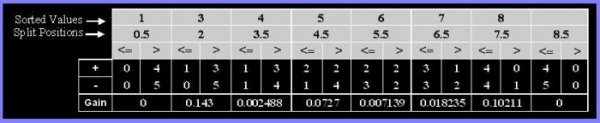

(d) What is the best split (between a1, a2, and a3) according to the information gain?
According to the information gain, the best split is a1 due to its higher gain in comparison to a2 and a3.
(e) What is the best split (between a1, and a2) according to the classification error rate?
According to the classificiation error rate, the best split is a1 due to a lower classification error in comparison to a2. The classification error depicts the accuracy of the sample set; the higher the classifiaction error the more error the sample set contains.
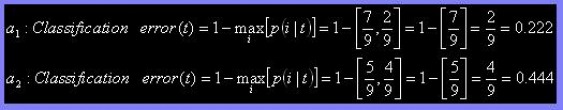
(f) What is the best split (between a1 and a2) according to the Gini index?
According to the Gini index, the best split is a1 due to its lower value in comparison to a2 depicting that a1 has a more even distribution.
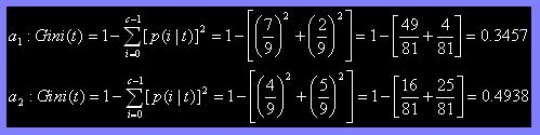
4.8.6
Consider the following set of training examples.
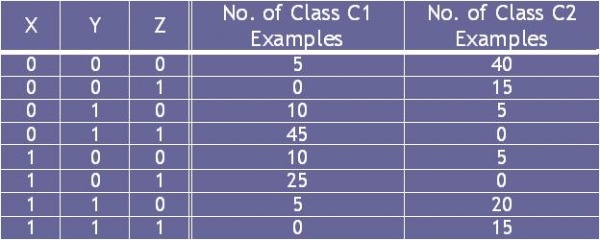
(a) Compute a 2-level decision tree using the greedy approach described in this chapter. Use the classification error rate as the criterion for splitting. What is the overall error rate of the induced tree?

(b) Repeat part (a) using X as the first splitting attribute and then choose the best remaining attribute for splitting at each of the 2 successor nodes. What is the error rate of the induced tree?

(c) Compare the results of parts (a) and (b). Comment on the suitability of the greedy heuristic used for splitting attribute selection.
When comparing the results from part (a) and (b), the suitability of the greedy heuristic does not produce optimum outcomes.
