Comp578 Susan Portugal Fall 2008
Assignment 6 October 9, 2008
5.10.12
Given the Bayesian network shown in Figure 5.48, compute the following probabilities:
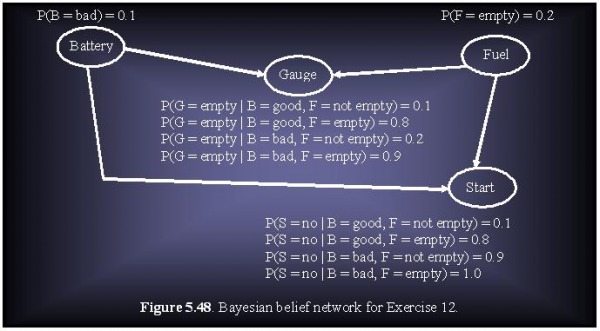
(a) P(B = good, F = empty. G = empty, S = yes).

(b) P(B = bad, F = empty, G = not empty, S = no).

(c) Given that the battery is bad, compute the probablility that the car will start.

5.10.13
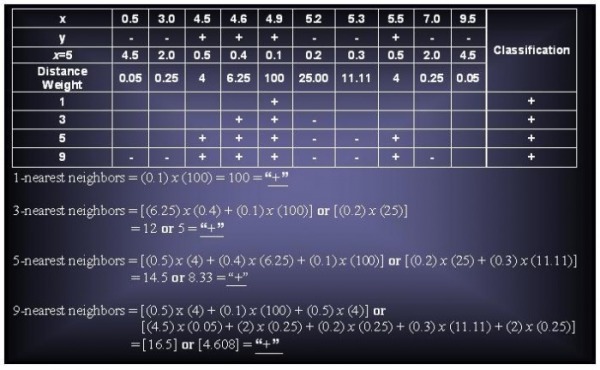
Consider the one-dimensional data set shown in Table 5.13.

(a) Classify the data point x = 5.0 according to its 1-, 3-, 5-, and 9-nearest neighbors (using majority vote).

(b) Repeat the previous using the distance-weighted voting approach described in Section 5.2.1.
5.10.16
(a) Demonstrate how the perceptron model can be used to represent the AND and OR functions between a pair of Boolean variables.

(b) Comment on the disadvantage of using linear functions as activation functions for multilayer neural networks.

5.10.17
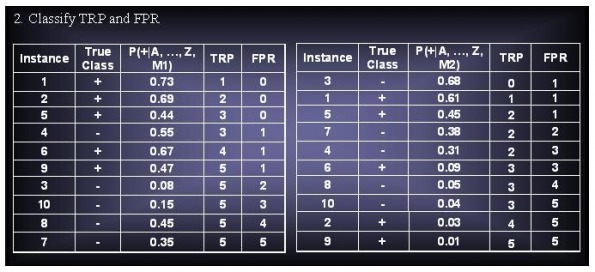
GYou are ased to evaluate the performance of two classification models, M1 and M2. The test set you have chosen contains 26 binary attributes, labeled as A through Z.
Table 5.14 shows the posterior probabilities obtained by applying the models to the test set. (Only the posterior probabilities for the positive class are shown). As this is a two-class problem, P(-) = 1 - P(+) and P(-|A, ..., Z). Assume that we are mostly interested in detecting instances from the positive class.
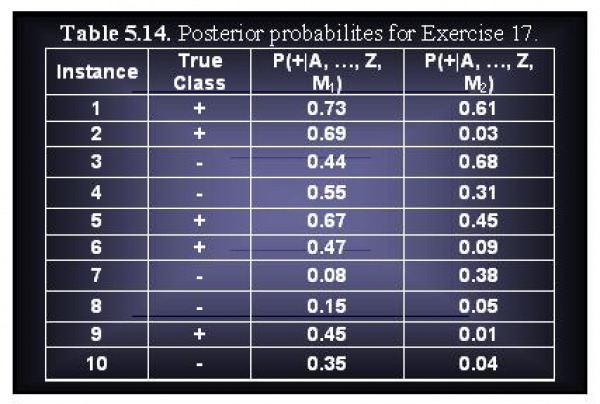
(a) Plot the ROC curve for both M1 and M2. (You should plot them on the same graph.) Which model do you think is better? Explain your reasons.
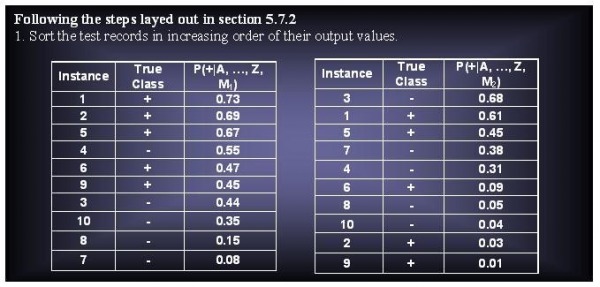
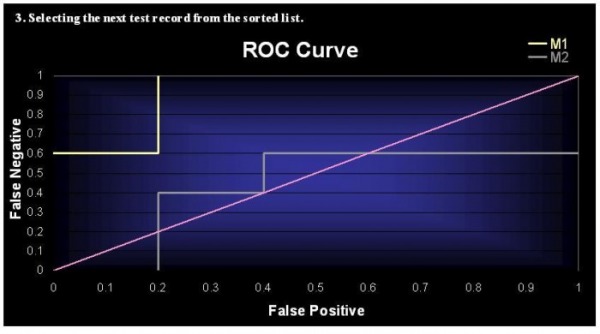
The preferred mode is M1 due to its higher value above the theoretical value and M2.
(b) For model M1, suppose you choose the cutoff threshold to be t = 0.5. In other words, any test instaces whose posterior probability is greater than t will be classified as a positive example. Compute the precision, recall, and F-measure for the model at this threshold value.

(c) Repeat the analysis for part (c) using the same cut off threshold on model M2. Compare the F-measure results for both models. Which model is better? Are the results consistent with what you expect from the ROC curve?

(d) Repeat part (c) for model M1 using the threshold t = 0.1. Which threshold do you prefer, t = 0.5 or t = 0.1? Are the results consistent with what you expect from the ROC curve?

